Exploring Mimi
The Scope of this Post
Today we are going to explore Mimi, a state-of-the-art neural audio codec developed by Kyutai. We will compare audio quality before and after Mimi processing, and we will then study how Mimi works and what types of outputs it produces.
What is Mimi?
Mimi codec is a state-of-the-art audio neural codec, developed by Kyutai, that combines semantic and acoustic information into audio tokens running at 12Hz and a bitrate of 1.1kbps.
This is the official description of Mimi from the Kyutai’s Huggingface repo.
Mimi is also the neural audio codec that powers Moshi (check moshi.chat for a demo), which we may discuss in a future post.
What is a Neural Audio Codec?
First, let’s define a codec: A codec, short for “coder-decoder” or “compressor-decompressor”, is a device or computer program that encodes or decodes a digital data stream or signal.
The primary purposes of codecs are to:
- Reduce file size for efficient storage
- Decrease bandwidth requirements for transmission
- Maintain an acceptable level of quality
An audio codec is a codec that encodes or decodes audio data. There exist two types of audio codecs:
- Lossy audio codecs: These compress audio by removing some data, resulting in smaller file sizes but with some loss in quality (e.g., MP3, AAC).
- Lossless audio codecs: These compress audio without losing any original data, maintaining perfect quality but with larger file sizes compared to lossy codecs (e.g., FLAC, ALAC).
A neural audio codec is a type of lossy audio codec that leverages artificial intelligence and machine learning techniques, neural networks in particular, to compress and decompress audio signals.
Some examples of neural audio codecs include:
- Lyra: Developed by Google, Lyra is a neural audio codec designed for low-bitrate speech compression
- EnCodec: Created by Meta AI, EnCodec is a high-fidelity neural audio codec that can compress audio at various bitrates while maintaining quality.
- SoundStream: Another neural audio codec developed by Google, focusing on high-quality audio compression at low bitrates.
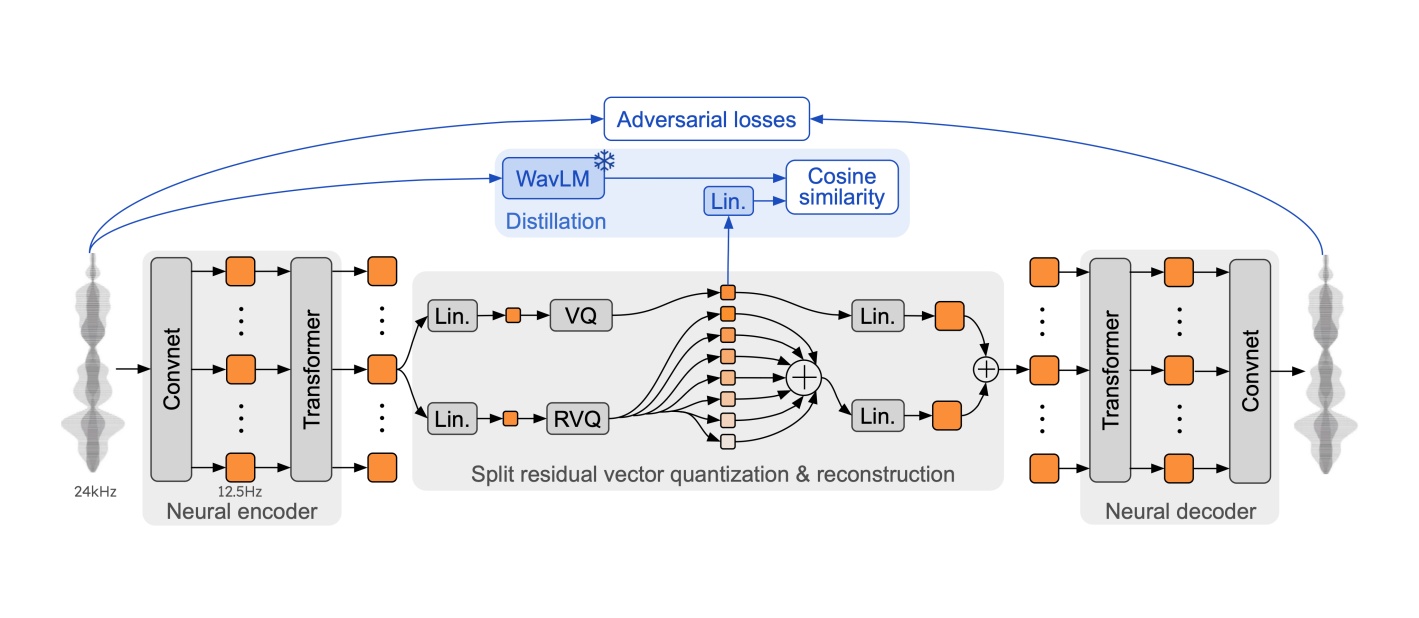
Mimi’s architecture is mostly derived from SoundStream and EnCodec, as stated in the official paper, although it has some novel features that set it apart.
Mimi in Detail
As mentioned earlier, Mimi is a neural audio codec that combines semantic and acoustic information into audio tokens, running at 12Hz and a bitrate of 1.1kbps. As such, Mimi is a fascinating codec that produces high-quality audio at an incredibly low bitrate.
Being an audio codec, Mimi is composed by two main components:
- An encoder: This component takes an audio signal as input and compresses it into a smaller representation.
- A decoder: This component takes the compressed representation and reconstructs the audio signal.
These are both neural networks, and can be visualized as a bottleneck architecture, where the audio signal is first compressed and then reconstructed.
The Encoding Process
The encoder compresses the audio signal into a sequence of audio codes, split into semantic and acoustic audio tokens. Here’s how it works:
- The audio signal is split into frames, each lasting 0.08 seconds, with a frame rate of 12.5Hz
- Each frame is passed through a convolutional neural network (CNN) and a transformer, which convert the frame into a vector of length 512.
- This vector is then passed through 8 quantizers, which quantize the audio signal into audio tokens (each quantizer produces 1 token per frame):
- 1 quantizer for the semantic tokens (which represent the content of the audio)
- 7 (according to the paper, see below for details) residual quantizers for the acoustic tokens (which represent the style of the audio)
- The quantized audio tokens are concatenated to produce a tensor of shape (batch_size, 8, frame_rate * audio_seconds)
This is a high-level overview of the encoding process. For a more detailed explanation, you can refer to the official paper.
Bitrate Calculation
Let’s calculate the bitrate of Mimi based on the information provided:
- Frame rate: 12.5Hz
- Number of audio tokens per frame: 8
- Number of bits per audio token: log_2(2048) = 11 (since there are 2048 possible audio tokens)
Therefore, the bitrate is calculated as: 12.5 * 8 * 11 = 1100 bits per second, or 1.1kbps, as advertised.
Although, here we find a discrepancy: the paper states that there are 8 audio tokens per frame, but the official implementation produces 32 audio tokens per frame, utilizing 32 quantizers instead of 8; This is significant as it quadruples the bitrate to 4.4kbps and makes us question if the results provided in the paper refer to the official implementation or to an actually 1.1kbps unreleased model.
A community post was made on the Huggingface forum to address this issue, but no official response has been given yet.
The Decoding Process
The decoder takes the quantized tokens and reconstructs the audio signal. It follows these steps:
- The tokens are passed through an inverse quantization process.
- The resulting embeddings are processed by another transformer network.
- Finally, a decoder CNN (mirroring the encoder’s CNN) reconstructs the audio waveform.
Audio Quality Comparison
In this section we are doing something more practical: we are going to compare the audio quality before and after Mimi’s processing (encoding and reconstruction).
The audio clips we are going to use are:
- The first sample from the hf-internal-testing/librispeech_asr_dummy validation dataset
- A Music Clip from the NCS YouTube channel
- A Japanese Speech Clip from the Sora The Troll Youtube channel
The clips will be presented as both the original audio and the audio after Mimi’s processing, so you can compare the quality for yourself. Keep in mind that the given original audios have been resampled to 24kHz, as Mimi only supports 24kHz audio.
The code we used to process the audio clips is available on my GitHub repository.
- Speech Clip
- Music Clip (Fourier, Reverse Prodigy, ZAM - Ares (Tear Up My Horizon) [NCS Release])
- Japanese Speech Clip
To better show the difference between the original and Mimi-processed audio clips, I am also attaching a waveform comparison for the music clip:
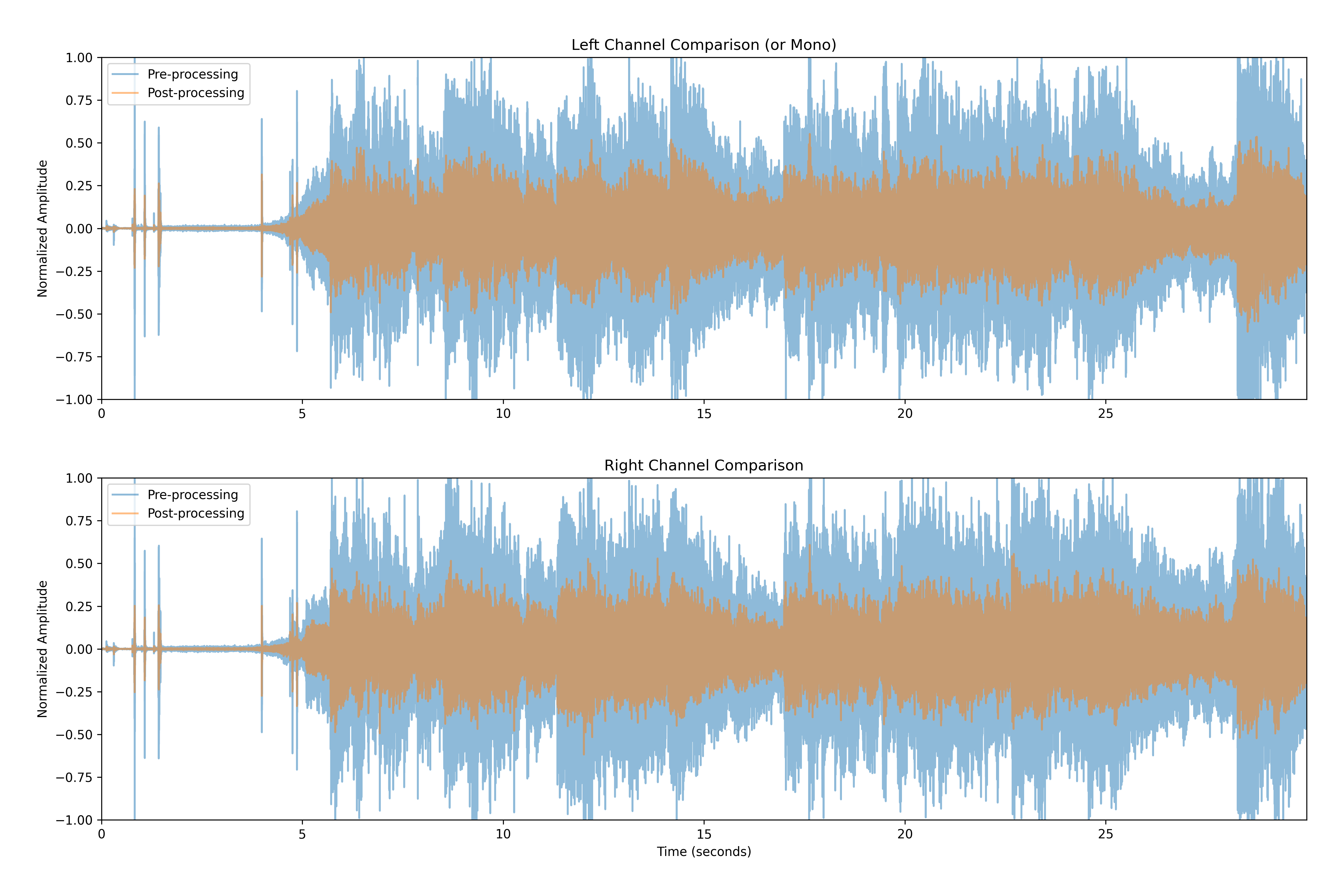
The light blue waveform represents the original audio, while the orange waveform represents the Mimi-processed audio; above is the left channel, below is the right channel.
As you can see (and hear) the Mimi-processed audio is quieter and has a lower dynamic range compared to the original audio, which is to be expected given the low bitrate of Mimi (although I am now curious to know how this same clip would sound with the 1.1kbps model). This results in less spatiality and detail in the audio, especially for music clips, but it still retains the overall structure and intelligibility of the original audio, making it suitable for speech applications.
Applications of Mimi
Mimi was primarily developed to power Moshi, a speech-to-speech AI model. To understand its significance, it’s important to know that current chat models (such as GPT and other Large Language Models, or LLMs) primarily operate on text tokens - discrete numerical representations of words or parts of words. These models aren’t inherently designed to process audio data.
This is where Mimi comes in. It bridges the gap between audio and text by converting audio into discrete tokens, similar to how text is tokenized. Mimi produces these audio tokens in a format that existing text-based LLMs can understand and process. This clever approach allows text-only models to support audio understanding and generation without requiring a complete overhaul of their architecture.
The implications of this are significant. Theoretically, we could fine-tune existing text-trained models to work with audio (as demonstrated with Moshi) by teaching them to interpret these audio tokens alongside text tokens. This is an exciting area that I plan to explore further in the future (so be sure to keep an eye on my blog!).
Moreover, this Mimi-LLM combination can also be used for speech-to-text and text-to-speech applications, as explored in the Moshi paper.
Conclusions
Mimi represents a significant step forward in the field of neural audio codecs. Its ability to compress audio to incredibly low bitrates while maintaining good quality, especially for speech, is impressive. The separation of semantic and acoustic information into distinct tokens is a novel approach that opens up new possibilities for audio processing and generation.
However, it’s important to note the discrepancies between the advertised specifications and the actual implementation. These differences, particularly in the number of quantizers and the resulting bitrate, raise questions about the exact performance metrics of the model described in the paper versus the one available for public use.
Despite these uncertainties, Mimi’s potential applications are exciting. Its integration with language models, as demonstrated by Moshi, points towards a future where open-source AI can more seamlessly interact with and generate audio content. Oh, also, did I mention that Mimi is ACTUALLY open-source? You can find the model on Huggingface.
I look forward to diving deeper into this and other architectures, and I hope you’ll join me on this journey :) Until next time, happy exploring!