Recent work from frontier labs has produced a wave of efficient hybrid architectures for Large Language Models (LLMs). 1Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models 1Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models 2IBM Granite 4.0: hyper-efficient, high performance hybrid models for enterprise 2IBM Granite 4.0: hyper-efficient, high performance hybrid models for enterprise 3Kimi Linear: An Expressive, Efficient Attention Architecture 3Kimi Linear: An Expressive, Efficient Attention Architecture 4Mamba-3: Improved Sequence Modeling using State Space Principles 4Mamba-3: Improved Sequence Modeling using State Space Principles These models typically combine multiple block types — convolutions, state-space models, and attention — to try and capture the benefits of each. Yet, the design process behind them is rarely documented: it is often unclear whether these architectures were systematically searched or simply engineered from intuition, and rigorous ablations of individual submodules are largely absent from the literature. As a result, it remains an open question how much each component actually contributes to the final model’s performance.
A shift in paradigm was recently brought to the research community by Liquid AI, with the release of their LFM2 architecture and its accompanying technical report.
On Liquid AI and LFM
Liquid AI is a Cambridge, Massachusetts-based artificial intelligence company founded in 2023. Its founders debuted with the concept of Liquid Neural Networks (LNNs): efficient networks inspired by the neural architecture of microscopic worms (C. elegans) and designed to be dynamic and adaptive, meaning they adjust their behavior based on inputs over time, much like biological neurons.
Building on that efficiency-first ethos, their research then shifted toward compact, edge-ready language models, culminating in the first Liquid Foundation Models (LFMs): a family of models that, notably, departed from the Transformer architecture that still mostly dominates the field.
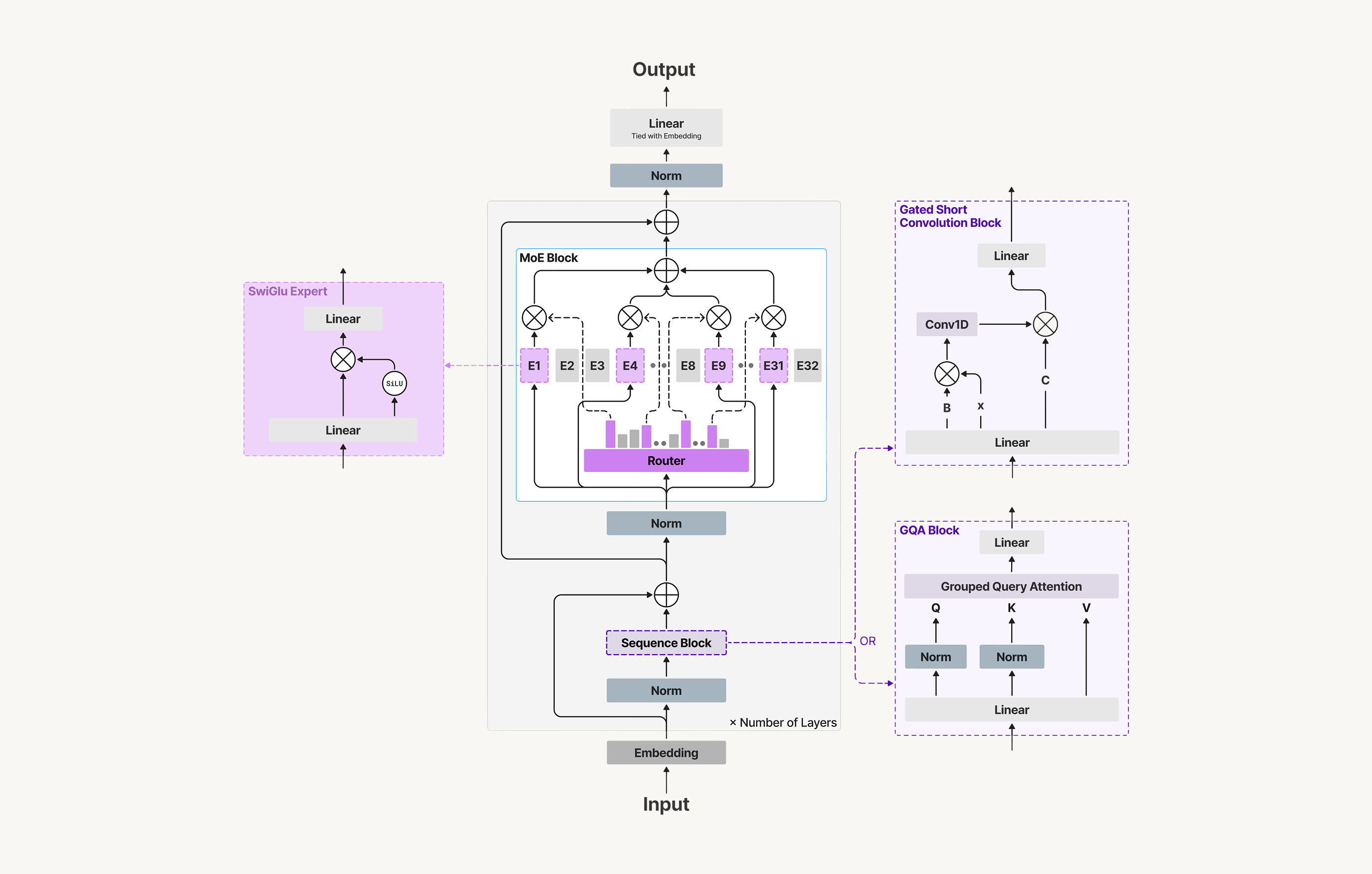
The first iteration of LFMs was released in 2024 and since then there have been gradual improvements in the architecture and training process, leading to the release of the LFM2 family of models in July of 2025. The LFM2 architecture is a hybrid design that combines gated short convolutions for local sequence mixing and a minority of Grouped Query Attention blocks for long-range token interaction. However, what sets it apart from other hybrid architectures — and what we are really interested in here — is the systematic approach taken to search for the optimal combination of components.
Neural Architecture Search
Neural Architecture Search (NAS) is nothing new: it has been a popular research topic for years, with the goal of automating the design of neural network architectures. The idea is to define a search space of possible architectures and then use an optimization algorithm to find the best one according to some performance metric (e.g., accuracy, latency, etc.). However, NAS can be computationally expensive and often relies on proxy signals (e.g., perplexity for quality, cache size for efficiency) to estimate the performance of candidate architectures without having to train them fully. Liquid AI already experimented on this concept in the past with STAR (Synthesis of Tailored ARchitectures): they found, however, that these proxy signals are not sufficient to capture the true performance of the architectures they were testing, especially when it came to the efficiency and latency of the models on real hardware.
As a result, in December of 2025, they published a paper introducing LFM2, a new iteration of the Liquid Foundation Models series, which utilized a novel NAS method that optimizes directly on an internal suite of 50+ evaluations (spanning knowledge recall, reasoning, multilingual robustness, tool use, math, and long-context tasks), real hardware latency and peak memory usage.
Defining a Search Space
If you are familiar with optimization problems, you probably already know that a search space represents all possible assignments to the decision variables that respect the basic type/domain restrictions of our problem (e.g., all 0–1 vectors of length 100, all integer tuples within certain bounds, all possible schedules, all graphs with n nodes, etc.).
In NAS, the search space is just about the same, but the possible assignements are neural network architectures — and in the case of LFM2, decoder only stacks built from different blocks families: local context and subquadratic blocks, 5Gated short convolutions, sliding-window attention, linear attention variants (GLA, HGRN2), state-space models (S4, Liquid-S4, S5, RTF, Mamba, Mamba2), and Liquid Time-Constant networks (CfC). 5Gated short convolutions, sliding-window attention, linear attention variants (GLA, HGRN2), state-space models (S4, Liquid-S4, S5, RTF, Mamba, Mamba2), and Liquid Time-Constant networks (CfC). global context blocks, 6Grouped-Query Attention (GQA) with varying group counts and head dimensions, stabilized with QK-Norm. 6Grouped-Query Attention (GQA) with varying group counts and head dimensions, stabilized with QK-Norm. position-wise blocks, 7SwiGLU FFNs whose expansion ratio is itself a search variable rather than fixed by hand. 7SwiGLU FFNs whose expansion ratio is itself a search variable rather than fixed by hand. plus layout 8Interleaving patterns of block types, total block counts under fixed parameter budgets, plus options for weight sharing and cache reuse across layers. 8Interleaving patterns of block types, total block counts under fixed parameter budgets, plus options for weight sharing and cache reuse across layers. and MoE options. 9Per-layer sparse FFNs with varying width and expert granularity. 9Per-layer sparse FFNs with varying width and expert granularity.
Architecture Search with Hardware-in-the-Loop
One of, if not the biggest innovation of this new NAS method is the use of real hardware-in-the-loop. In the paper, architectures are tested directly against a a Samsung Galaxy S24 Ultra (Qualcomm Snapdragon 8 Gen 3 SoC) and aAMD Ryzen HX 370 laptop CPU by recording:
- Time To First Token (TTFT),
- prefill throughput (tokens/s),
- decode ms/token (p50/p95 10p50: median decode latency — the "typical" speed a user experiences. p95: the slowest 5% of tokens fall above this threshold, capturing occasional spikes from cache pressure or scheduling jitter. 10p50: median decode latency — the "typical" speed a user experiences. p95: the slowest 5% of tokens fall above this threshold, capturing occasional spikes from cache pressure or scheduling jitter.), and
- peak memory at target context windows sizes (4K and 32K) on release runtimes.
Candidates that violate any device-side budget on TTFT, decode latency, or peak memory are discarded outright and they never make it to the quality evaluation stage.
Pareto Optimization
With the remaining feasible candidates, the question becomes: how do we find an optimal architecture?
Since quality, latency, and memory are competing objectives (an architecture that scores better on quality evaluations will often have above-average latency and memory usage, and vice versa) compromises are necessary. This is exactly the setting that Pareto optimization was designed for: a multi-objective decision-making framework for finding solutions where no single objective can be improved without making at least one other objective worse.
A solution is marked as Pareto optimal if there is no other solution that strictly improves on all objectives simultaneously. The set of all Pareto-optimal solutions forms the Pareto frontier — any point on the frontier is a valid “best” choice.
In practice, the paper ranks surviving candidates by their hypervolume improvement on the quality–latency–memory Pareto frontier. The hypervolume metric measures how much a new candidate expands the “volume” of space dominated by the current frontier, collapsing the three-axis trade-off into a single scalar that makes candidates directly comparable. Those that advance the frontier are carried forward; those that don’t are dropped.
What the Search Actually Found
The most striking result is what the search converged on, despite the breadth of the search space. Across all size targets, the hardware-in-the-loop search repeatedly selected the same minimal hybrid: a majority of inexpensive gated short convolution blocks, interleaved with a small minority of GQA blocks — and nothing else. SSMs, linear attention variants, Mamba, and other subquadratic operators were all valid candidates, and under the targeted on-device CPU budgets and runtimes, none improved the quality–latency–memory tradeoff over the final simple hybrid.
Conclusions
The LFM2 architecture search is, in effect, a broad ablation of the hybrid design space — something that is largely absent from the literature on similar models. SSMs, linear attention variants, Mamba, and a range of other subquadratic operators were all valid candidates, and all were consistently outcompeted by the simplest possible hybrid.
That is the part worth sitting with. The field has spent considerable effort designing increasingly complex hybrid architectures, often motivated by theoretical arguments about what each component should contribute. Liquid AI’s approach bypasses that reasoning entirely: rather than engineering a design from intuition and post-hoc justifying it, they let the hardware and the downstream tasks speak for themselves.
The answer, it turns out, is that once you have a handful of global attention layers to handle long-range retrieval, the inexpensive gated short convolution alone appears sufficient. Complexity is not always a necessity — and without a systematic search to prove it, we would have no principled way of knowing that.
Disclosure: this post was proofread for grammar and style with Claude Sonnet 4.6. The analysis and conclusions remain my own.